

Ask any programmer and they’ll tell you what they think about JavaScript.
Since the time it was released, JavaScript (JS) has been the most popular programming language used by web developers across the globe. A recent survey by Stack Overflow among web developers reveals that JavaScript is the most preferred programming language for eight years in a row.
JS allows web developers to build large-scale web applications with ease. It has an exceptional ability to dynamically update pages and make them more interactive. Moreover, JavaScript frameworks like AngularJS, ReactJS, Vue, and NodeJS significantly reduce the amount of time and effort needed for developing JS-based sites. No wonder JavaScript forms the basis of 96 percent of websites globally.
Yet JS-based sites seem to have a love-hate relationship with Google. JavaScript can easily control and alter HTML to make the web pages dynamic and interactive, thus improving the site’s UX. Yet search engines find it tough to deal with JS, leaving most of the JavaScript content unindexed.
Let’s dig a little deeper into why JavaScript makes Google’s job tougher and what you can do to make your JS content bot-friendly.
JavaScript allows the pages to load quickly, offers a rich interface, and is easy to implement; however, the browser fluidity changes based on the user interaction, making it tough for search engines to understand the page and associate a value to the content.
Search engines have their limitations when rendering web pages that carry JavaScript content. Google performs an initial crawl of the page and indexes what it finds. As resources are available, the bots go back to rendering JS on those pages. This means the content and links relying on JavaScript run the risk of not being seen by search engines, potentially harming the site’s SEO.
However, Google knows that JavaScript is here to stay! As a result, the search engine giant has dedicated much of its resources to help search professionals optimize their JS-based sites.
Check out this video series on JavaScript SEO from Google that can help make your JS content more discoverable online.
SEO experts need to wrangle their JS-based web pages in a format that Google appreciates. With a little understanding of how search engines process JS content, JavaScript and SEO can be made to work together to boost your site’s ranking.
Google bots process JS differently than a non-JS page. Bots process them in three phases, namely crawling, indexing, and rendering. These phases can be easily understood thanks to the graphic from Google Developers below:
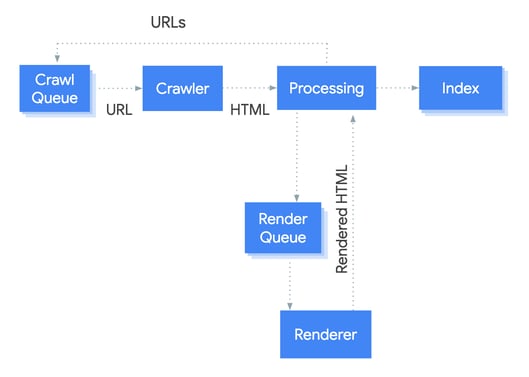
This phase is about the discoverability of your content. It’s a complicated process, involving subprocesses, namely seed sets, crawl queuing and scheduling, URL importance, and others.
To begin with, Google’s bots queue the pages for crawling and rendering. The bots use the parsing module to fetch pages, follow links on the pages, and render until a point when the pages are indexed. The module not only renders pages but also analyzes the source code and extracts the URLs in the <a href=”…”> snippets.
The bots check the robots.txt file to see whether or not crawling is allowed. If the URL is marked disallowed, the bots skip it. Therefore, it’s critical to check the robots.txt file to avoid errors.
The process of displaying the content, templates, and other features of a site to the user is called rendering. There is server-side rendering and client-side rendering.
As the name suggests, in this type of rendering the pages are populated on the server. Each time the site is accessed, the page is rendered on the server and sent to the browser.
In other words, when a user or bot accesses the site, they receive the content as HTML markup. This usually helps the SEO as Google doesn't have to render the JS separately to access the content. SSR is the traditional rendering method and may prove to be costly when it comes to the bandwidth.
Client-side rendering is a fairly recent type of rendering that allows developers to build their sites entirely rendered in the browser with JavaScript. So, instead of having a separate HTML page per route, client-side rendering allows each route to be created dynamically directly in the browser. Though this type of rendering is initially slow as it makes multiple rounds to the server, once the requests are complete the experience through the JS framework is fast.
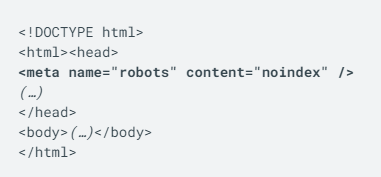
Coming back to what happens after a page has been crawled, the bots identify the pages that need to be rendered and add them to the render queue unless the robots meta tag in the raw HTML code tells Googlebot not to index the page.
The pages stay in the render queue for a few seconds, but may take some time, depending on the amount of resources available.
Once the resources allow, the Google Web Rendering Service (WRS) renders, parses, and compiles the pages and executes the JavaScript on the page. The bot parses the rendered HTML for links again and queues the URLs it finds for crawling. The rendered HTML is used for indexing the page.
Once the WRS fetches the data from external APIs and databases, the Caffeine indexer on Google can index the content. This phase involves analyzing the URL, understanding the content on the pages and its relevance, and storing the discovered pages in the index.
JavaScript, when implemented incorrectly, can ruin your SEO. Follow these Javascript SEO best practices to improve your site’s ranking.
All the on-page SEO rules that go into optimizing your page to help them rank on search engines still apply. Optimize your title tags, meta descriptions, alt attributes in images, and meta robot tags. Unique and descriptive titles and meta descriptions help users and search engines easily identify the content. Pay attention to the search intent and the strategic placement of semantically-related keywords.
Also, it’s good to have an SEO-friendly URL structure. In a few cases, websites implement a pushState change in the URL, confusing Google when it’s trying to find the canonical one. Make sure you check the URLs for such issues.
JavaScript rendering works when the DOM of a page has sufficiently loaded. The DOM or Document Object Model shows the structure of the page content and the relationship of each element with the other. You can find it in the browser’s ‘‘Inspect element’ on the page code. DOM is the foundation of the dynamically-generated page.
If your content can be seen in the DOM, chances are your content is being parsed by Google. Checking the DOM will help you determine whether or not your pages are being accessed by the search engine bots.
Bots skip rendering and JS execution if the meta robots tag initially contains noindex. Googlebot doesn't fire events at a page. If the content is added to the page with the help of JS it should be done after the page has loaded. If the content is added to the HTML when clicking the button, when scrolling the page, and so so, it won't be indexed.
Finally, when using structured data, use JavaScript to generate the required JSON-LD and inject it into the page. As an aside, learn about the top on-page SEO tricks you should be implementing from the get-go.
To avoid the issue of Google not being able to find JS content, a few webmasters use a process called cloaking that serves the JS content to users but hides it from crawlers. However, this method is considered to be a violation of Google’s Webmaster Guidelines and you could be penalized for it. Instead, work on identifying the key issues and making JS content accessible to search engines.
At times, the site host may be unintentionally blocked, barring Google from seeing the JS content. For instance, if your site has a few child domains that serve different purposes, each should be having a separate robots.txt because subdomains are treated as a separate website. In such a case, you need to make sure that none of these robots.txt directives are blocking search engines from accessing the resources needed for rendering.
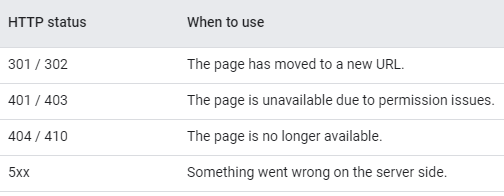
Google’s crawlers use HTTP status codes to identify issues when crawling a page. Therefore, you should use a meaningful status code to inform the bots if a page shouldn’t be crawled or indexed. For instance, you could use a 301 HTTP status to tell the bots that a page has moved to a new URL, allowing Google to update its index accordingly.
Refer to this list of HTTP status codes and know when to use them:
When JavaScript is used for websites, there may be different URLs for the same content. This causes duplicate content issues, often caused by capitalization, IDs, or parameters with IDs. Make sure you find such pages, choose the original/preferred URL you want indexed, and set canonical tags to avoid search engines from getting confused.
Site speed is critical for SEO. Lazy loading is one such UX best practice that defers the loading of non-critical or non-visible content, thus reducing initial page load time. But besides making pages load faster, you also need to ensure that your content is accessible to search engine crawlers. These crawlers won’t execute your JavaScript or scroll the page to drive lazy-loaded content, negatively affecting your SEO.
What’s more, image searches are also a source of additional organic traffic. So if you have lazy-loaded images, search engines will not pick them. While lazy loading is great for users, it needs to be done with care to prevent bots from missing potentially critical content.
There is an abundance of tools available that can help you identify and fix issues with JavaScript code. Here are a few you can use to your advantage.
By now you have a fair idea of how search engines process JavaScript content and what you can do to set your website on the fast track to SEO success. However, there are a few other challenges faced by SEO experts and webmasters. Most of these stem from the mistakes committed by them when optimizing their JavaScript-based websites
If you’re using SEO tools to audit your JS website, you would have probably come across a warning regarding issues with unminified Javascript and CSS. Over a period of time, JS and CSS files are weighed down by unnecessary code lines, white spaces, comments in source code, and hosting on external servers, making your website slow. Make sure you get rid of the unnecessary lines, white spaces, and comments to reduce the load time of the pages, improve engagement rate, and boost SEO.
Remember what John Mueller said about bad URLs at an SEO event?
“For us, if we see kind of the hash there, then that means the rest there is probably irrelevant. For the most part, we will drop that when we try to index the content…”
Yet several JS-based sites generate URLs with a hash. This can be disastrous for your SEO. Make sure your URL is Google-friendly. It should definitely not look like this:
www.example.com/#/about -us OR
www.example.com/about#us
Google requires proper <a href> links to find URLs on your site. Also, if the links are added to the DOM after clicks on a button, the bots will fail to see them. Most webmasters miss out on these points, causing their SEO to suffer.
Take care to provide the traditional ‘href’ link, making them reachable for the bots. Check your links using the website audit tool, SEOprofiler to improve your site’s internal link structure.
Check out this presentation by Tom Greenway during the Google I/O conference for guidance on a proper link structure:
Without a doubt, JavaScript expands the functionality of websites. However, JavaScript and search engines don’t always go together. JavaScript impacts the way search engines crawl and index a site, thus affecting its ranking. Therefore, search professionals must understand how search engine bots process JS content and take the necessary steps to ensure that JavaScript fits well into their SEO strategy.
If you have a JS-based website and cannot find your content on Google, it’s time to address the issues. Use the information and tips shared in this post to optimize JavaScript for SEO and boost your returns.


Over the years, on-page SEO practices, for the most part, have remained the same.
 by Manick Bhan
by Manick Bhan

Slow and steady doesn't always win the race.
 by Yoni Solomon
by Yoni Solomon

Technical SEO. A short phrase that has been known to strike fear into the hearts of SEOs and...
 by Ken Marshall
by Ken Marshall