
Term frequency inverse document frequency (TF-IDF) is a contentious term frequently mentioned within the content marketing and SEO space.
Some people claim it’s a secret content optimization weapon while others are more skeptical. In this post, we examine what TF-IDF is along with a look at its limitations and where it’s used.
And don’t worry – we’ll go easy on the math.
TF-IDF is a formula intended to reflect the importance of a word (term) in document within a collection (corpus).
To understand TF-IDF we need to go back to 1957, decades before the world wide web, to the work of Hans Peter Luhn, a computer science researcher at IBM. He notes that the more frequently a term or combination of terms appears, “the more importance the author attaches to them”. In other words, the importance (weight) of a term is proportional to its frequency.
This raw count of a term in a document can be mathematically described as follows:
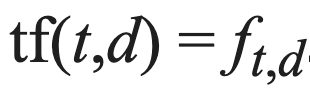
Term frequency (TF) is equal to the number of times (frequency) a term is found in a given document. Although beyond the scope of this article, note that the formula can be modified to account for situations such as document length and long-document bias.
However, there’s a problem.
Frequently used words like and, but, the, a, I, and you will be weighted highly due to their frequent usage, even though they are not important concepts.
Which brings us to the metric called inverse document frequency (IDF). IDF was conceived by Karen Spärck Jones in 1972 as a way of damping the weighting of common terms and increasing the weighting of those that occur infrequently.
IDF is used to determine whether a term is common or rare across a corpus. Common words have less informational value as opposed to ones that occur rarely. It is defined as a “logarithmically scaled inverse fraction of the documents that contain the word.”
It looks like this:
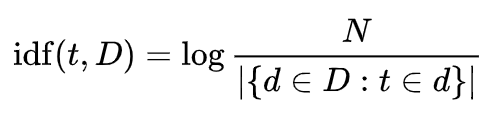
No doubt this is a mathematical mouthful, but the important thing to remember is that this formula reduces the weighting of those common words like and, a, and the that have little informational value.
So, put TF and IDF together and you get this:
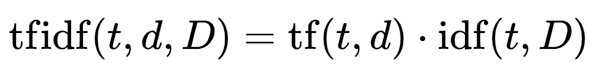
Enough of the math already!
The key point is that a high term weighting is the result of a high term frequency in a given document and a low term frequency in the collection.
The way the function works, the more often a term appears in the corpus, the ratio approaches 1, bringing idf and tf-idf closer to 0. So those common words will have little weighting.
As with TF, there are variants of the IDF weighting scheme including inverse document frequency smooth, inverse document frequency max, and probabilistic inverse document frequency.
Those are great terms you can use to impress your content marketing coworkers. But we’ll leave it at that!
Spärck Jones first refers to IDF as term specificity in 1972 paper. Although it’s a practical method, it’s far from optimal, and from a theoretical perspective, it’s open to some serious challenges.
Content marketers also have a problem using TF-IDF based tools for a number of reasons. TF-IDF was created for informational retrieval purposes, not content optimization as some people have put forward. TF-IDF is a formula that counts the frequency of a term in a document within a corpus and dampens the weighting of terms that occur too frequently.
That’s it.
Thus, it can’t deal with:
It’s a stretch of the imagination to take these output from TF-IDF and equate it to any kind of semantic relationship. The formula account for gross overweightings that occur from words used too frequently. But it can’t account for the nuances in between.
Here’s an example to clarify.
The top 10 list of weighted terms according to TF-IDF for the phrase “content strategy” includes:
This brings about a number of questions, including:
TF-IDF tools typically depend on the top 10 or 20 results in Google, but that can’t give you a complete picture. When confronted with heavily fractured search intent, these tools are more likely to lead you astray. TF-IDF doesn’t solve your content and SEO problem, it just makes you feel good.
Given the challenges that using TF-IDF poses, are there any situations in which this algorithm is being used? Yes, but it’s not a standalone solution, it’s just one component.
Saying that you use TF-IDF for optimizing content is like saying you use spreadsheets for content marketing. You’re not saying much.
Sure it has its limitations, but in certain contexts TF-IDF can be useful. According to a study published in International Journal on Digital Libraries, “TF-IDF was the most frequently applied weighting scheme.”
TF-IDF works well for finding stop words, like “a, an, in, and, the,” that appear very often in many documents. Since stop word removal is a component of text summarization, TF-IDF can play an important role in this application.
A more novel usage of TF-IDF can be found in Matching Images With Textual Document Using TF-IDF Method, published in the 2012 5th International Congress on Image and Signal Processing. But I know what you’re thinking.
It’s time to address the elephant in the room. Does Google use TF-IDF?
Google’s search algorithm is no doubt a big and sophisticated beast. So there’s a fair chance they incorporate TF-IDF in some fashion.
But don’t get too excited. In this video, the only context in which John Mueller, Senior Webmaster Trends Analyst, mentioned TF-IDF was for stop word removal.
While efficient at removing stop words, TF-IDF plays a limited role in natural language processing. So, we should avoid over emphasizing its role in search engine optimization.
Some people swear that TF-IDF historically correlates with higher rankings. But correlation is not causation. It may be the act of improving the content itself that brings about a benefit, and not the content analysis tool itself.
Care to learn about adjacent content marketing tools? See the top-rated content marketing software out there today.



The aim of a distributed denial of service (DDoS) attack is to overwhelm a network or server...
 by Sagar Joshi
by Sagar Joshi

The world of nonprofits can be a confusing place for anyone not familiar with the terminology.
 by Lauren Pope
by Lauren Pope

From figuring out what to pack to scheduling an itinerary,, preparing for a business trip can...
 by Rob Browne
by Rob Browne