Customer queries don’t really have a working-hours limit. However, imagine being able to provide an instant, helpful response no matter the time the customer asks the question.
That’s the promise of generative AI virtual assistants and chatbots - a 24/7 digital concierge.
The AI-powered tool has taken the load off customer support teams while keeping customers happy with quick, personalized responses.
Yet, there is a plot twist: While companies are going all-in on this technology, with research showing the global chatbot market is expected to grow from $5.64 billion in 2023 to $16.74 billion by 2028, customers aren’t exactly rushing to embrace it. In fact, 60% of consumers prefer human interaction over chatbots when it comes to understanding their needs.
This mismatch suggests we might need to rethink how we approach and design this technology. After all, what good is a revolutionary tool if people aren’t ready to embrace it?
One of the main reasons why chatbots have not yet caught on is that they are mostly built without considering user experience. Having a conversation with such a chatbot would mean going through the painful experience of repeated responses to different queries and almost no contextual awareness.
Imagine your customer is trying to reschedule a flight for a family emergency, only to be stuck in an endless loop of pre-written responses from the virtual assistant asking if you want to “check flight status” or “book a new flight.” This unhelpful conversation, devoid of the personal human touch, would just drive customers away.
This is where generative AI or GenAI may transform chatbot interactions and empower your customer support teams. Unlike traditional chatbots, which rely on written responses, generative AI tools and models can comprehend and grasp user intent, resulting in more personalized and contextually aware responses.
With the ability to generate responses in real time, a GenAI-powered assistant could recognize the urgency of the flight rescheduling request, empathize with the situation, and seamlessly guide the user through the process—skipping irrelevant options and focusing directly on the task at hand.
Generative AI also has dynamic learning capabilities, which enable virtual assistants to alter their behavior based on previous encounters and feedback. This means that over time, the AI virtual assistant improves its ability to anticipate human needs and provide more natural support.
In order to fully realize the possible potential of chatbots, you need to go above the mere functionality of chatbot services to develop more user-friendly, enjoyable experiences. This means that virtual assistants handle consumer demands proactively instead of reactively.
We’ll walk you through the five “fuel” design principles of creating the optimum GenAI interactive virtual assistant that will help you respond to user queries better.
As AI models become smarter, it relies on gathering the correct data to provide accurate responses. Retrieval-augmented generation (RAG), through its industry-wide adoption, plays a huge role in providing just that.
RAG systems, through external retrieval mechanisms, fetch information from relevant data sources like search engines or company databases that mainly exist outside its internal databases. These systems, coupled with large language models (LLMs), formed the basis for generating AI-informed responses.
However, while RAG has certainly improved the quality of answers by using relevant data, it struggles with real-time accuracy and vast, scattered data sources. This is where federated retrieval augmented generation (FRAG) could help you.
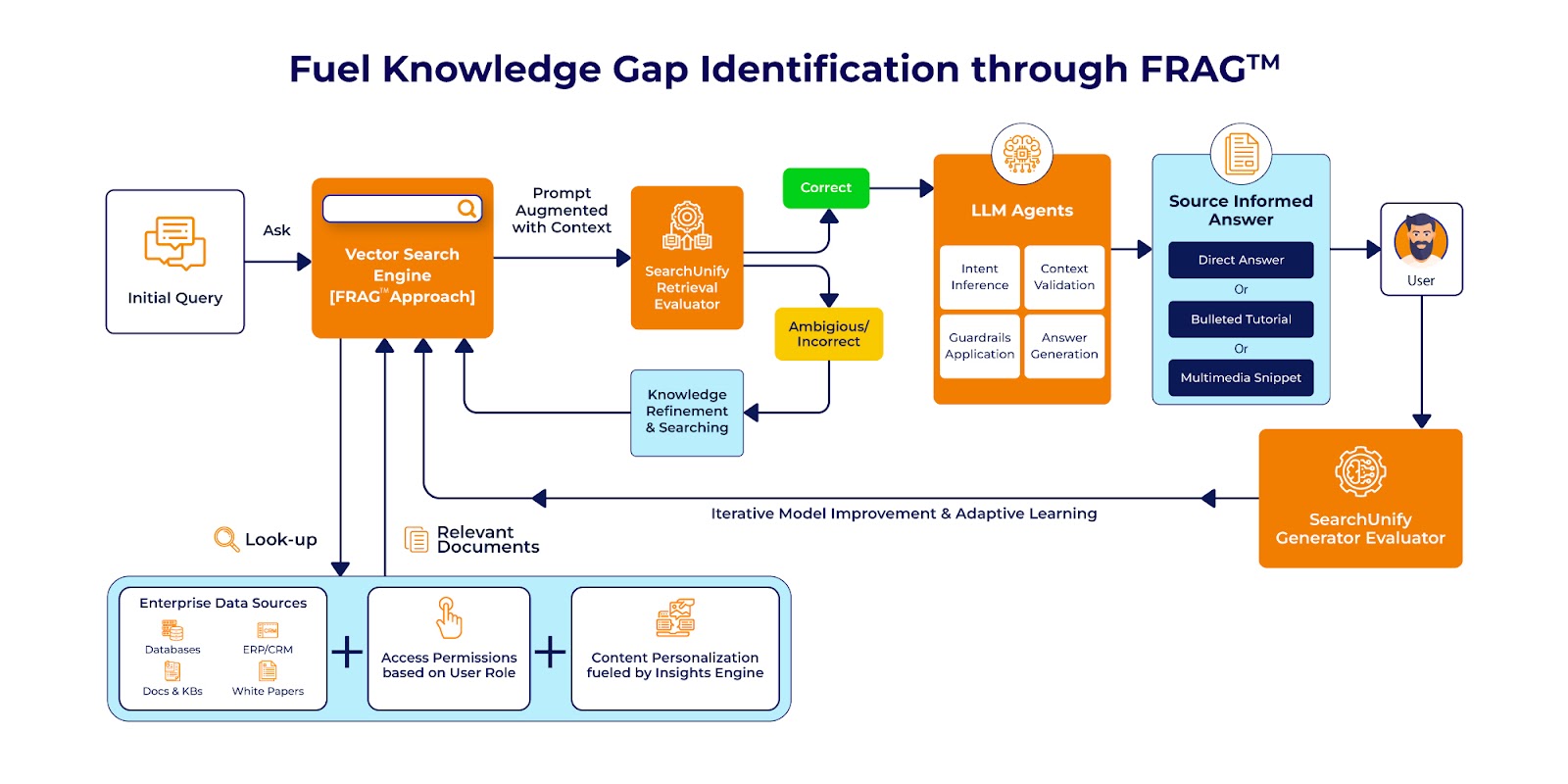
FRAG takes the idea behind RAG to the next level by solving two major issues mentioned before. It can access data from different, disconnected data sources (called silos) and make sure the data is relevant and timely. Federation of data sources is done through connectors, this allows different organizational sources or systems to share knowledge which is indexed for efficient retrieval, thus improving the contextual awareness and accuracy of generated responses.
If we were to break down how FRAG works, it contains the following pre-processing steps:
Source: SearchUnify
Now that we’ve covered the basics of how FRAG works. Let’s look into the details of how it can further improve your GenAI virtual assistant’s response with better contextual information.
When you input a query, the AI model doesn’t just search for exact matches but tries to find an answer that matches the meaning behind your question using contextual retrieval.
This is the data retrieval phase. It ensures that the most appropriate, fact-based content is available to you for the next step.
A user query is translated to an embedding - a numerical vector that reflects the meaning behind the question. Imagine you search for "best electric cars in 2024." The system translates this query into a numerical vector that captures its meaning, which is not just about any car but specifically about the best electric cars and within the 2024 time frame.
The query vector is then matched against a precomputed, indexed database of data vectors that represent relevant articles, reviews, and datasets about electric cars. So, if there are reviews of different car models in the database, the system retrieves the most relevant data fragments—like details on the best electric cars launching in 2024—from the database based on how closely they match your query.
While the relevant data fragments are retrieved based on the similarity match, the system checks for access control to ensure you are allowed to see that data, such as subscription-based articles. It also uses an insights engine to customize the results to make them more useful. For example, if you had previously looked for SUVs, the system might prioritize electric SUVs in the search results, tailoring the response to your preferences.
Once the relevant, customized data has been obtained, sanity tests are carried out. Should the obtained data pass the sanity check, it is sent to the LLM agent for response generation; should it fail, retrieval is repeated. Using the same example, if a review of an electric car model seems outdated or incorrect, the system would discard it and search again for better sources.
Lastly, the retrieved vectors (i.e., car reviews, comparisons, latest models, and updated specs) are translated back into human-readable text and combined with your original query. This enables the LLM to produce the most accurate results.
This is the response synthesis phase. After the data has been retrieved through vector search, the LLM processes it to generate a coherent, detailed, and customized response.
With contextual retrieval the LLM has a holistic understanding of the user intent, including factually relevant information. It understands that the answer you are looking for is not about generic information regarding electric cars but specifically giving you information relevant to the best 2024 models.
Now, the LLM processes the enhanced query, pulling together the information about the best cars and giving you detailed responses with insights like battery life, range, and price comparisons. For example, instead of a generic response like “Tesla makes good electric cars,” you’ll get a more specific, detailed answer like “In 2024, Tesla’s Model Y offers the best range at 350 miles, but the Ford Mustang Mach-E provides a more affordable price point with similar features.”
The LLM often pulls direct references from the retrieved documents. For example, the system may cite a specific consumer review or a comparison from a car magazine in its response to give you a well-grounded, fact-based answer. This ensures that the LLM provides a factually accurate and contextually relevant answer. Now your query about “best electric cars in 2024” results in a well-rounded, data-backed answer that helps you make an informed decision.
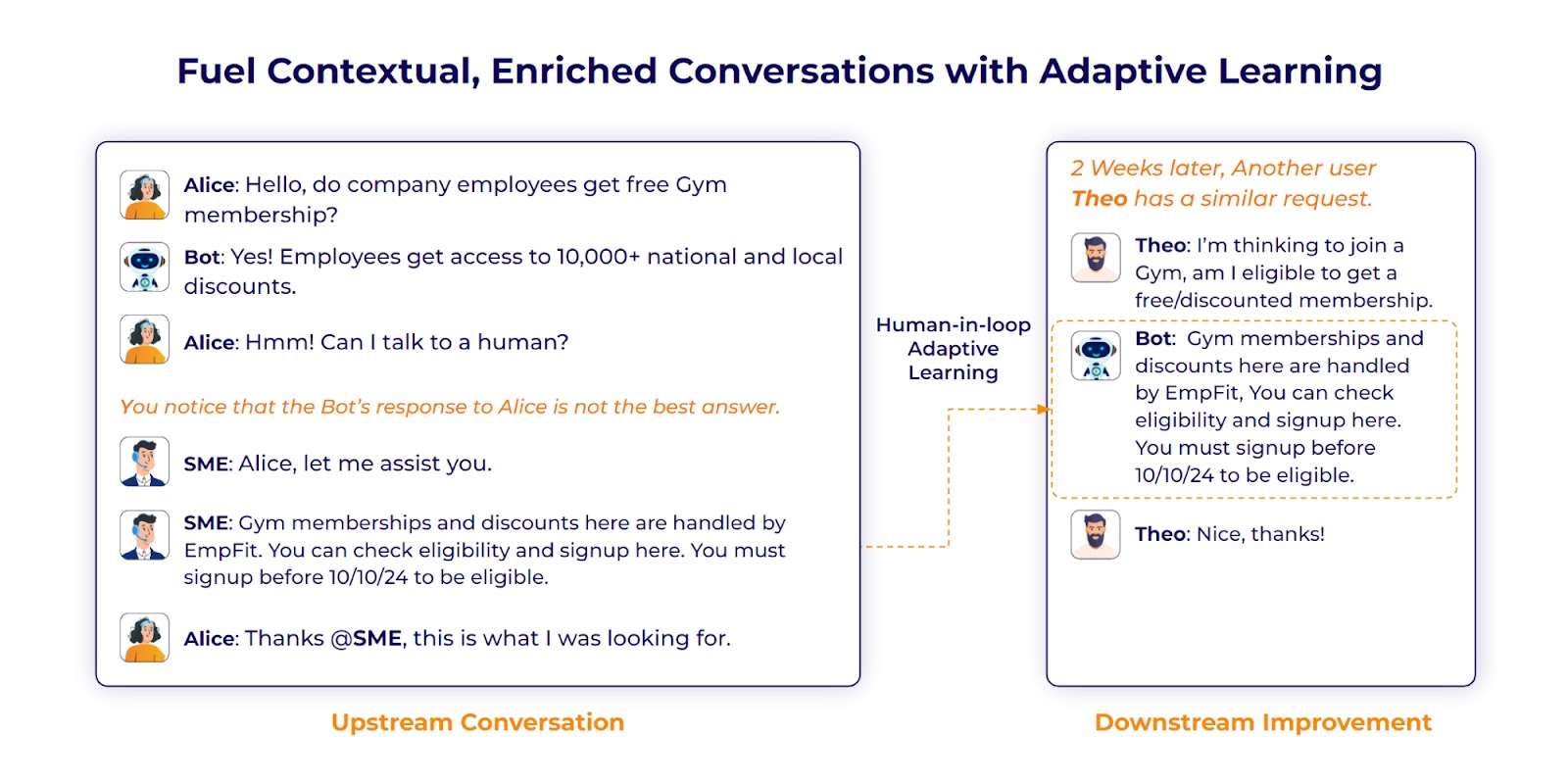
Training and maintaining an LLM is not all that easy. It can be both time consuming and resource intensive. However, the beauty of FRAG is that it allows for continuous learning. With adaptive learning techniques, such as human-in-the-loop, the model continuously learns from new data available either from updated knowledge bases or feedback from past user interactions.
So, over time, this improves the performance and accuracy of the LLM. As a result, your chatbot becomes more capable of producing answers relevant to the user's question.
Source: SearchUnify
Having a generative fallback mechanism is essential when you are working on designing your virtual assistant.
How does it help?
When your virtual assistant can’t answer a question using the main LLM, the fallback mechanism will allow it to retrieve information from a knowledge base or a special fallback module created to provide a backup response. This ensures that your user gets support even if the primary LLM is unable to provide an answer, helping prevent the conversation from breaking down.
If the fallback system also cannot help with the user's query, the virtual assistant could escalate it to a customer support representative.
For example, imagine you’re using a virtual assistant to book a flight, but the system doesn't understand a specific question about your luggage allowance. Instead of leaving you stuck, the assistant’s fallback mechanism kicks in and retrieves information about luggage rules from its backup knowledge base. If it still can’t find the right answer, the system quickly forwards your query to a human agent who can personally help you figure out your luggage options.
This hybrid approach with automated and human help will result in your users receiving faster responses leaving satisfied customers.
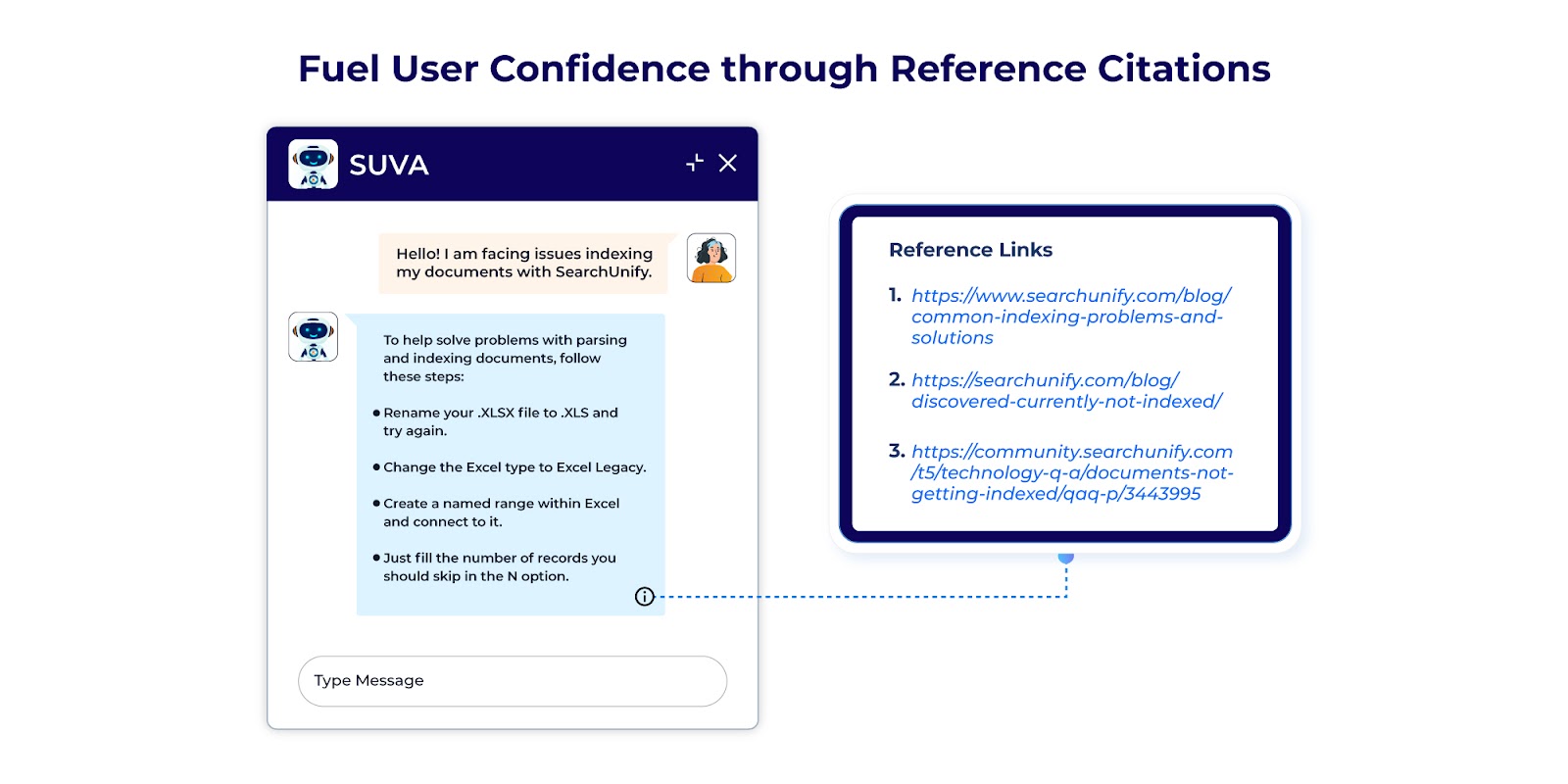
Including reference citations when designing your virtual assistants will allow you to improve trust among your users when it comes to the answers delivered.
Transparency is at the core of user trust. So providing these reference citations goes a long way in solving the dilemma that LLMs deliver answers that are unproven. Now your virtual assistant's answers will be backed by sources that are traceable and verifiable.
Your chatbot can share relevant documents or sources of information it depends on when producing the responses with the user. This would shed light for the user on the context and reasoning behind the answer while allowing them to cross-validate the information. This also gives the added bonus of allowing the user to dig deeper into the information if they wish to do so.
With reference citations in your design, you can focus on the continuous improvement of your virtual assistant. This transparency would help with identifying any errors in the answers provided. For example, if a chatbot tells a user, "I retrieved this answer based on a document from 2022," but the user realizes that this information is outdated, they can flag it. The chatbot's system can then be adjusted to use more recent data in future responses. This type of feedback loop enhances the chatbot's overall performance and reliability.
Source: SearchUnify
When designing a chatbot, you need to understand that there is value in creating a consistent personality.
While personalizing conversations should be top of mind when designing a chatbot, you should also ensure its persona is clearly defined and consistent. This will help your user understand what the virtual assistant can and cannot do.
Setting this upfront will allow you to define your customer’s expectiations and allow your chatbot to easily meet them, enhancing customer experience. Make sure the chatbot’s persona, tone, and style correspond with user expectations to achieve confidence and predictability when it engages with your customer.
The most effective design of a virtual assistant shows a mix of convergent and divergent ideas. The convergent design guarantees clarity and accuracy in response by looking for a well-defined solution to a problem. The divergent design promotes innovation and inquiry as well as several possible answers and ideas.
In virtual assistant design, temperature control and prompt injection fit into both convergent and divergent design processes. Temperature control can dictate whether the chatbot leans towards a convergent or divergent design based on the set value, while prompt injection can shape how structured or open-ended the responses are, influencing the chatbot’s design balance between accuracy and creativity.
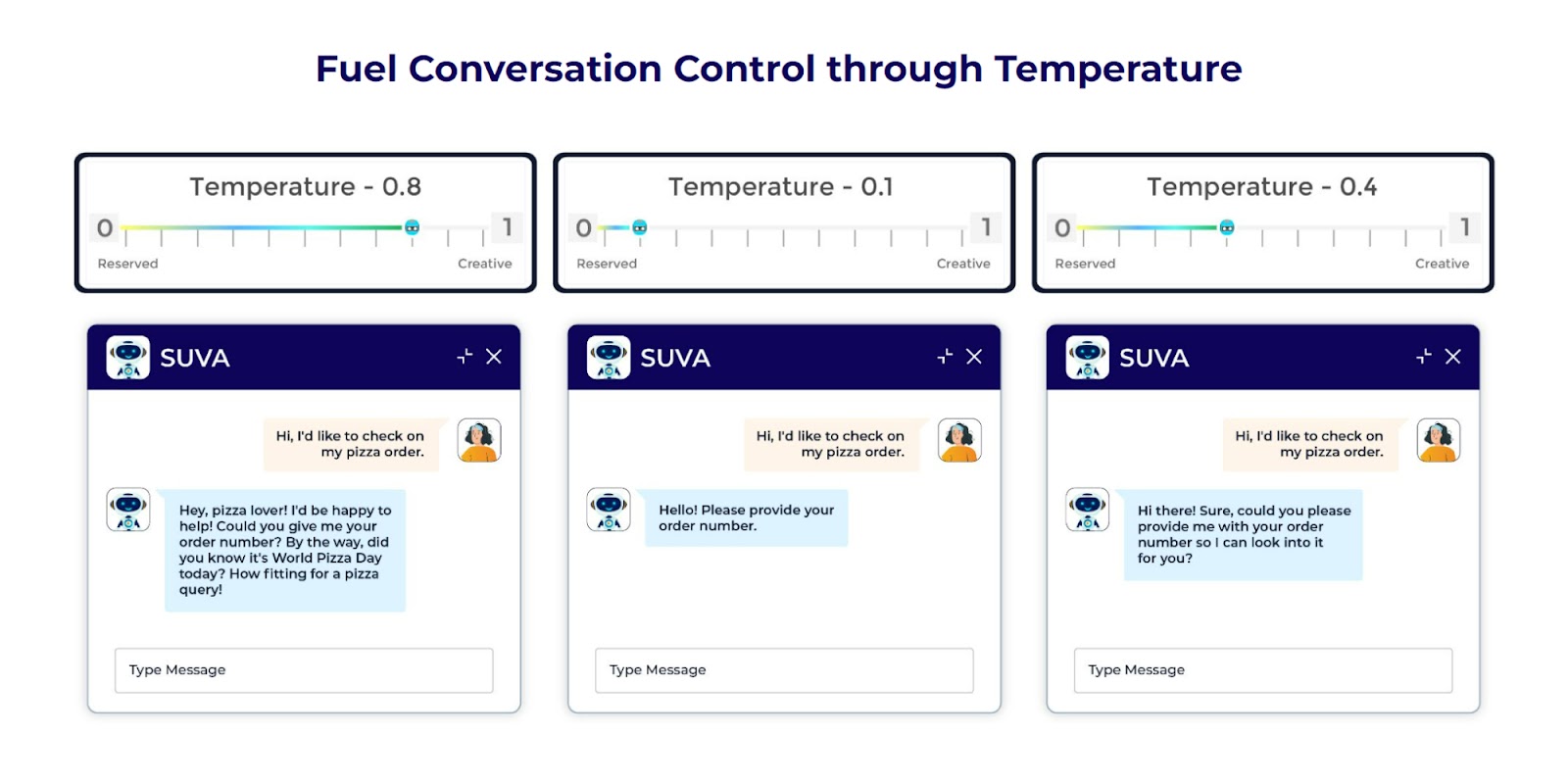
Temperature control is a way to govern the originality and randomness of your chatbot. Its purpose is to regulate variation and creativity in the produced outputs by a language model.
Let’s discuss temperature control's effects on chatbot performance as well as its mechanisms.
When it comes to functionality, a temperature between 0.1 and 1.0 is employed ideally as a pointer in the LLM applied in a chatbot design. A lower temperature near 0.1 will push the LLM toward cautious replies which are more in line with the user prompt and knowledge base obtained information. Less likely to add surprising features, the answers will be more factual and trustworthy.
On the other hand, a greater temperature - that which approaches 1.0 - helps the LLM generate more original and interesting answers. Thus, integrating the inventive aspects of the chatbot, which offers far more various responses from the given prompt, greatly helps to produce a much more human-like and dynamic conversation. But with more inventiveness comes the possibility of factual errors or pointless information.
What are the advantages? Temperature control lets you carefully match your chatbot's answer style to the kind of situation. For factual research, for instance, accuracy could take front stage, and you would desire a lower temperature. Creative inspiration via "immersive storytelling" or problem-solving ability calls for a greater temperature.
This control will allow for temperature change as per user inclination and context to make your chatbot’s answer more pertinent and appealing. People looking for thorough knowledge would value straightforward answers, while consumers looking for unique content would appreciate inventiveness.
What are the considerations to keep in mind?
By including these techniques in your chatbot design, you guarantee a well-rounded approach that balances dependability with creativity to provide an ideal user experience customized to different settings and preferences.
Source: SearchUnify
Experimenting with several stimuli to improve and enhance the performance of a virtual assistant is among the most important things you can do.
You can experimentally change the prompts to improve the relevance and efficacy of your conversational artificial intelligence system.
Here is a methodical, organized approach to play about with your prompts.
Semantic search is the sophisticated information retrieval approach that uses natural language models to improve result relevance and precision, which we have talked about before.
Unlike a traditional keyword-based search, which is mainly based on match, search semantics keeps user queries in mind based on the meaning and context they are asking. It retrieves information based on what a person might want to search for – the underlying intent and conceptual relevance instead of simple keyword occurrences.
Semantic search systems use complex algorithms and models that analyze context and nuances in your user queries. Since such a system can understand what words and phrases mean within a broader context, it can identify and return relevant content if the exact keywords haven't been used.
This enables more effective retrieval of information in line with the user's intent, thus returning more accurate and meaningful results.
The benefits of semantic search include:
To beat the statistics of 60% of consumers preferring human interaction over chatbots involves a thoughtful design strategy and understanding all the underlying problems.
With a fine-tuned and personalized design approach to your virtual assistant, your company will fuel user confidence with one breakdown-free and accurate response at a time.
Curious about how voice technology is shaping the future of virtual assistants? Explore our comprehensive guide to understand the inner workings and possibilities of voice assistants.
Edited by Shanti S Nair


Someone told me the other day that we live in strange times – we ask our watches to make calls...
.jpg) by Daria Zaboj
by Daria Zaboj

With AI capabilities, cloud telephony has evolved beyond simple call routing to enabling more...
 by Aamir Malik
by Aamir Malik

We use search engines all the time, but we aren’t always the best at asking questions.
 by Brooks Manley
by Brooks Manley