.png?width=400&height=150&name=Untitled%20design%20(56).png)

Companies that need online transactions cannot afford server breakdowns. As a result, these businesses seek ways to create a failsafe procedure that keeps their data safe even if the server collapses. One such method is failover clustering.
Failover clustering can be governed by managed domain name system (DNS) provider solutions; however, understanding its mechanism and key features can help limit any failover challenges.
Failover clustering is a high-availability solution where multiple servers work together to ensure continuous service. If one server fails, another automatically takes over. This setup minimizes downtime for applications, databases, or services by using shared resources and constant health monitoring.
This approach keeps your server workloads scalable and available. Many major server programs, such as Microsoft Exchange, Microsoft SQL Server, and Hyper-V, rely on failover clustering to protect themselves.
Some failover clusters employ physical servers, while others use virtual machines (VMs). Everyone selects the kind of cluster they need based on the requirements of their server application.
A cluster consists of two or more nodes that exchange data and software to be processed through physical cables or a specialized secure network. Clustering technology of several types can be used for load balancing, storage, and concurrent or parallel computing. In some instances, failover clusters are combined with extra clustering technologies.
A failover cluster's primary function is to provide continuous availability (CA) or HA for applications and services. CA clusters, also known as failure-tolerant (FT) clusters, let end-users continue using applications and services even if a server fails. You might see a brief interruption in service caused by HA clusters, but the system can recover with no data loss and little downtime.
Failover clustering and load balancing are often used together in IT infrastructure, but they serve fundamentally different purposes.
| Aspect | Failover Clustering | Load Balancing |
| Primary goal | Redundancy and high availability | Performance optimization and traffic distribution |
| Core function | Automatically shifts workloads to a standby node when a failure occurs | Distributes traffic or processing evenly across multiple active nodes |
| Node setup | Typically active-passive | Typically active-active |
| Ideal use case | Mission-critical applications where downtime impacts data, revenue, or customer trust | Applications or services that need to handle high traffic and maintain responsiveness |
| Key benefit | Keeps services alive during failures with minimal disruption | Prevents any single node from becoming overwhelmed and optimizes resource usage |
| Common deployment | Used to ensure uptime and data integrity | Often placed in front of failover clusters for balanced performance and resilience |
Put simply, failover clustering keeps services running when failures occur, while load balancing keeps them running efficiently under heavy load. In many modern architectures, both are combined: load balancing sits in front of a failover cluster to deliver both uptime protection and resource optimization.
With failover clustering, you can repair inactive nodes without shutting down your database, avoiding downtime concerns while quickly repairing broken servers. Furthermore, in the event of a hardware failure, this technique terminates the database to protect the active nodes.
Failover clustering also automates data recovery in the event of a failure. This reduces your reliance on the information technology (IT) crew and allows your servers to recover quickly. It also delivers excellent structured query language (SQL) cluster availability with minimal downtime. The automated failover functionality of failover clustering preserves the function of your database, even if there’s a hardware breakdown.
Failover clustering consists of two fundamental processes, HA and CA, for server applications.
While CA failover clusters try to reach 100% availability, HA clusters strive for 99.999%, commonly known as five nines. This downtime totals no more than 5.26 minutes each year. CA clusters have higher availability but require more hardware to operate, increasing their overall cost.
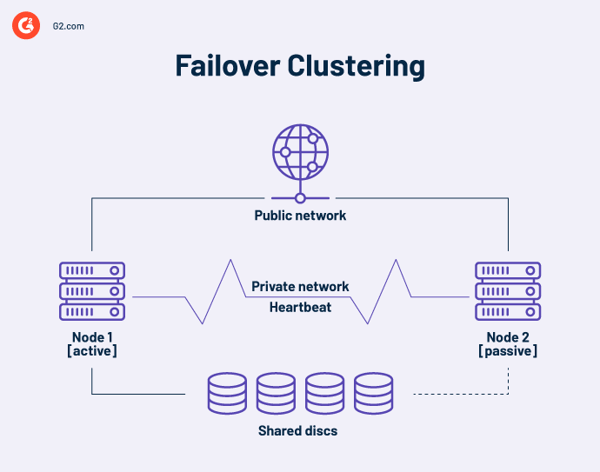
A high availability cluster is a collection of independent computers that share resources and data. A failover cluster's nodes have access to shared storage. A monitoring link is also included in high-availability clusters to check the other servers' heartbeat or health. A heartbeat is a private network shared only by the nodes in the cluster. It’s not accessible from the outside.
At any point, at least one node in a cluster is active, and at least one is dormant or passive.
In a basic two-node arrangement, if Node 1 fails, Node 2 recognizes the failure via the heartbeat connection and configures itself as the active node. Clustering software on each node guarantees that clients connect to an active node.
Larger installations may employ dedicated servers to administer the cluster. A cluster management server always sends heartbeat signals to identify failing nodes and, if so, tell another node to take over the work.
Some cluster management software tools handle HA for VMs by grouping the machines and servers into a cluster. If a host fails, a different host resumes the VMs.
Shared storage represents a risk as a possible single failure point. However, combining a redundant array of independent disks 6 and 10 — aka RAID 6 and RAID 10 — can help maintain service even if two hard drives fail.
Electrical power might be another single point of failure if all servers are connected to the same grid. Providing each node with its own uninterruptible power supply (UPS) keeps them protected.
Unlike the HA paradigm, a fault-tolerant cluster comprises numerous computers that share a single copy of a computer's operating system (OS). Software commands given to one system are also executed on the other systems.
CA insists that the organization employs formatted computer equipment and a backup UPS. CA needs a constantly accessible and almost perfect replica of the physical or virtual system running the service. This redundancy model is known as 2N.
CA systems can compensate for a wide range of faults. A fault-tolerant system may identify a malfunction of:
The failure point may be discovered promptly, and a backup component or method can take its place immediately without disrupting the next service.
Clustering software can connect two or more servers to behave as a single virtual server or construct various alternative CA failover cluster configurations. For instance, if one of the virtual servers fails, the others respond by temporarily removing it from the cluster quorum. The virtual server then redistributes the burden across the other servers until the crashed server is ready to restart.
A double hardware server with all physical components replicated is an alternative to CA failover clusters. They compute separately and concurrently on various hardware platforms and synchronize using a dedicated node that monitors the results from both physical servers. While this solution provides protection, it may be more expensive.
HA and CA clustering both aim to keep services running with minimal disruption, but they differ significantly in their tolerance for downtime and infrastructure complexity. For example, an e-commerce company might tolerate 5 minutes of downtime annually with an HA cluster. But a real-time trading platform? It can’t afford even a second, which is where CA clusters shine.
HA clusters are designed for near-perfect uptime, typically targeting 99.999% availability, commonly known as “five nines”, which equates to just over five minutes of allowable downtime per year. These setups use redundant nodes and shared storage to detect failures and quickly switch workloads. However, a brief interruption may still occur during the failover process.
CA clusters, in contrast, are built for zero downtime. Even if a component fails, be it a CPU, power supply, or an entire server, the application keeps running without missing a beat. This is achieved through synchronized, parallel systems that execute the same operations simultaneously, often requiring mirrored hardware and far more intricate orchestration.
In short:
Both improve system resilience, but CA typically demands higher investment and architectural complexity.
Significant advancements in failover clustering have occurred in the last decade, with many organizations now offering their own version of clustering solutions. Some of the most common cluster services are detailed here.
VMware provides numerous virtualization technologies for VM clusters. The vSphere vMotion’s CA architecture precisely duplicates a VMware virtual machine and its network between physical data center networks.
VMware vSphere HA, a second product, provides HA for VMs by grouping them and their hosts into a cluster for automated failover. Additionally, the program does not rely on external components such as DNS, which lowers possible points of failure.
The Windows Server Failover Cluster (WSFC) method fosters the creation of Hyper-V failover servers. Between 2016 and 2019, this strategy grew popular among Microsoft Windows users. WSFC allows cluster monitoring and offers the necessary failover mechanism automatically. In the event of a server loss, WFSC moves the clusters to a separate node or attempts to restart them. Additionally, its CSV technology provides a distributed namespace that allows several nodes to share memory.
This Microsoft product, introduced with SQL Server 2017, has robust HA solutions that use WSFC technology. SQL Server components are considered WSFC cluster resources in this context. They’re further integrated with other WSFC-dependent resources. As a result, WSFC has authority over identifying and communicating orders to restart a SQL server instance or to move instances like those to a new node.
Other than Microsoft, other operating system vendors come with their own failover cluster solutions. For example, Red Hat Enterprise Linux (RHEL) fans can use the HA extension and Red Hat Global File System (GFS/GFS2) to establish HA failover clusters. Single-cluster stretch clusters spanning many locations and multi-site, disaster-tolerant clusters are supported. Storage area network (SAN) data storage replication is commonly used in multi-site clusters.
This robust mechanism facilitates the following real-time applications.
Online transaction processing (OLTP) computers must have fault-resistant systems. OLTP, which requires complete availability, is used for airline reservation systems, electronic stock trading, and ATM banking.
Many industries, such as manufacturing, shipping, and retail, employ CA clusters or failure-resistant computers for mission-critical applications. E-commerce, order management, and staff time clock systems count as examples.
High availability clusters are often acceptable for clustering applications and services that require only five-nines uptime.
Disaster recovery also benefits from failover clustering. It is strongly recommended that failover servers be hosted at remote sites because a calamity such as a fire or flood destroys all physical hardware and software.
Storage Replica, a technology that duplicates volumes between servers for disaster recovery, is included in Windows Server 2016 and 2019. Stretch failover is a technology feature that lets failover clusters span two locations.
Extending failover clusters allows organizations to replicate data across various centers. If tragedy strikes at one location, all data is preserved on failover servers at the others.
According to Microsoft, the WSFC was first launched in Windows Server 2016 to safeguard "mission-critical" services, like its SQL server database and Microsoft Exchange communications server.
Other vendors supply failover cluster technology for database replication. For example, MySQL Cluster has a heartbeat method that enables fast failure detection to other nodes in the cluster, often in under a literal second, with no service disruptions to clients.
Databases may be replicated to faraway sites using the geographic replication capability.
Implementing a failover cluster is a structured process that requires the right hardware, software, and orchestration to ensure seamless availability. Whether you're deploying in a traditional data center or a hybrid cloud environment, these key steps will help you build a resilient, high-availability system.
Start by identifying the mission-critical workloads you want to protect. Is this for SQL Server? Virtual machines? File shares? Your intended use case will influence how many nodes you need, what type of shared storage to implement (e.g., SAN, cluster shared volumes (CSV), or cloud-based disks), and whether your cluster requires HA or CA.
Also, make sure:
On each node (server), install the necessary failover clustering components. In Windows Server environments:
For Linux-based clusters, install the appropriate cluster stack (e.g., Corosync and Pacemaker on Red Hat or Debian distributions).
Run a cluster validation tool (e.g., the Cluster Validation Wizard in Windows Server) to verify that your nodes are configured correctly. This tool checks:
Only proceed if the cluster passes all required validation checks.
Use your cluster management interface (like Failover Cluster Manager in Windows) to create the cluster:
After creation, test that the cluster is recognized and operational.
Add workloads that should be highly available, such as:
Each workload becomes a cluster role and should be configured with startup policies, preferred owners (nodes), and failover priority.
Manually simulate failures to confirm your setup works. For example:
If configured properly, the cluster should fail over automatically with minimal or no user impact.
Integrate your cluster with monitoring systems like System Center, Zabbix, or Nagios to alert you when nodes fail, resources move, or disk performance degrades. You can also:
Monitoring is key for proactive maintenance and long-term reliability.
For external-facing services, integrate a managed DNS provider that can route users to the correct cluster node or site, even if a node fails or a region goes offline. Providers like Cloudflare DNS and Azure DNS offer health check-based traffic steering that complements your failover setup.
The idea of failover clusters is to ensure that users experience minimal service disruptions. However, other additional benefits of failover clustering are discussed below.
As significant as failover clustering is, it comes up against the following limitations.
Choosing a reliable managed DNS provider is critical for ensuring fast, secure, and resilient network performance, especially as uptime and global reach become non-negotiables for digital businesses.
Based on G2’s Summer 2025 Grid® Report, the following are the top-rated managed DNS software solutions, ranked by verified user reviews and market presence:

Clusters use a heartbeat mechanism, a dedicated communication channel that continuously checks each node's status. If a node stops responding, the system detects the failure and initiates a failover process to reroute workloads.
Yes. Platforms like VMware vSphere and Microsoft Hyper-V support failover clustering for virtual machines. If a host server fails, the cluster automatically moves VMs to another healthy node to keep services running without manual intervention.
In most traditional failover cluster setups, shared storage is required to give all nodes access to the same data and application files. This is typically managed using technologies like SAN, NAS, or Cluster Shared Volumes. Some modern systems use data replication to avoid a single point of failure in storage.
Yes. Managed DNS services can monitor server health and automatically redirect traffic to backup nodes or data centers during an outage. This enhances the effectiveness of your failover system by ensuring users are always routed to a functioning endpoint.
Industries that require constant uptime rely heavily on failover clustering. These include financial services, healthcare, manufacturing, telecommunications, government, and e-commerce sectors, where even brief downtime can have serious consequences.
Failover clustering has emerged as a reliable and essential option for high availability and fault tolerance within current IT infrastructures. It provides ongoing operations despite hardware failures or scheduled maintenance by automatically spreading workloads and resources across numerous networked nodes. This technology gives you another way to handle the most important aspect of your business – making each customer’s experience safe and happy.
Fortifying your system’s resilience doesn’t hurt, either!
Get started with a guide to DNS security for a robust system strategy.
This article was originally published in 2023. It has been updated with new information.
.png)

Servers handle the requests your browser makes while you’re online. Two types of servers...
 by Sagar Joshi
by Sagar Joshi

Data loss, no matter the cause, is a threat to organizations. The 3-2-1 backup strategy helps...
 by Praveen E
by Praveen E

Your organization’s digital offering - its software interfaces, websites, and applications -...
 by Priya Khaira-Hanks
by Priya Khaira-Hanks